Logistička regresija
Anica Kostić
18 аpril 2018
Modelom logističke regresije opisujemo vezu između prediktora koji mogu biti neprekidni, binarni, kategorički, i kategoričke zavisne promenljive. Na primer zavisna promenljiva može biti binarna - na osnovu nekih prediktora predviđamo da li će se nešto desiti ili ne. Ocenjujemo zapravo verovatnoće pripadanja svakoj kategoriji za dat skup prediktora. U zavisnosti od tipa zavisne promenljive imamo
Binarnu logističku regresiju - zavisna promenljiva je binarna. Na primer: proći ili pasti test, odgovor da ili ne u anketi, visok ili nizak krvni pritisak
Nominalna logistička regresija - zavisna promenljiva ima 3 ili više kategorija koje se ne mogu po vrednosti upoređivati. Na primer: boje (crna, crvena, plava,…), internet pretraživač (Google, Bing, Yahoo!,…) itd.
Ordinalna logistička regresija - zavisna promenljiva ima 3 ili više kategorija koje se prirodno mogu upoređivati, ali rangiranje ne mora da znači da su “rastojanja” između njih jednaka. Na primer: ocena (5-10), zdravstveno stanje (dobro, stabilno, ozbiljno, kritično) itd. Logistička regresija koristi kada zavisna promenljiva uzima samo neki konačan skup vrednosti.
Da li ipak možemo koristiti linearnu regresiju
Pitamo se da li ipak možemo koristiti linearnu regresiju u problemima klasifikacije. U slučaju binarne logističke regresije smatramo da je zavisna promenljiva Bernulijeva slučajna veličina. Tada imamo dve kategorije koje kodiramo sa \(0\) - za neuspeh i \(1\) za uspeh.
\[ Y= \begin{cases} 0, \quad \text{neuspeh} \\ 1, \quad \text{uspeh} \end{cases} \]
Dakle zavisna promenljiva je Bernulijeva ne neka neprekidna slučajna veličina. Zbog toga, greške ne mogu biti normalne. Takođe, ako bismo ipak sproveli linearnu regresiju dobili bismo neke besmislene fitovane vrednosti - vrednosti izvan skupa \(\{0,1\}\).
U slučaju binarne zavisne promenljive jedan način da koristimo linearnu regresiju za problem klasifikacije može biti sledeći: za dati skup prediktora, ako je fitovana vrednost linearnom regresijom veća od 0.5, onda tu opservaciju klasifikujemo kao uspeh, inače kao neuspeh. Ovaj metod tada je ekvivalentan linearnoj diskriminantnoj analizi, o kojoj ćemo kasnije. Ovim metodom dobijamo samo klasifkaciju za neku opservaciju: “uspeh” ili “neuspeh”. Ako su fitovane vrednosti linearnom regresijom blizu 0.5, onda smo manje sigurni u našu odluku, ali pošto te fitovane vrednosti pripadaju celom skupu realnih brojeva, kako da odredimo koja vrednost iz \(\mathbb{R}\) znači koji nivo sigurnosti?
Na primer, korisnije nam je da možemo da ocenimo verovatnoću da je neki zahtev osiguranju za isplatu odštete prevara, nego samo da ga klasifikujemo kao prevaru ili ne.
Još ćemo reći da, ako zavisna promenljiva uzima više od dve vrednosti, onda se ne može koristiti linearna regresija kao što smo opisali malopre, nego linearna diskriminantna analiza.
Model logističke regresije
Ovde ćemo se baviti binarnom logističkom regresijom. Model višestruke binarne logističke regresije dat je sledećom jednačinom
\[\begin{align}\label{logmod} \pi&=\frac{\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{p-1}X_{p-1})}{1+\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{p-1}X_{p-1})}\notag \\ & =\frac{\exp(\textbf{X}\beta)}{1+\exp(\textbf{X}\beta)}\\ & =\frac{1}{1+\exp(-\textbf{X}\beta)} \end{align}\]gde \(\pi\) predstavlja verovatnoc1u da opservacija pripada kategoriji zavisne promenljive koju smo označili kao uspeh. Ovim modelom opisuje se verovatnoća događaja kao funkcija prediktora \(X\).
Pomenuli smo da je \(y\) Bernulijeva slučajna veličina. U stvari smatramo da \(y_i|\bf{X}=\bf{x}_i\) ima Bernulijevu raspodelu sa parametrom \(\pi_i\). Primetimo da je kod linearne regresije ova uslovna raspodela bila normalna. Na primer, verovatnoća da neka osoba ima bolest srca. Iz izraza za \(\pi\) jasno je da uzima vrednost između 0 i 1. Ako imamo samo jedan prediktor, onda se model može grafički prikazati, oblik funkcije \(\pi\) u odnosu na \(X\) tada ima takozvani sigmoidni oblik, a asimptote su u beskonačnosti 0 i 1. Ovaj model zove se logistička regresija jer se funkcija \(f(x)=\frac{e^x}{e^x+1}=\frac{1}{1+e^-x}\) zove logistička funkcija, a u logističkom modelu zavisna promenljiva je logistička funkcija linearne funkcije prediktora. Logistička funkcija zove se i logit funkcija.
Formulacija preko latentne varijable
Neka je \(Y_i\) binarna zavisna promenljiva, njene vrednosti znamo iz uzorka. Pretpostavimo da postoji neka sakrivena slučajna veličina čije vrednosti ne možemo da vidimo, \(Y_i^*\) koja može da uzme bilo koju realnu vrednost. Pretpostavimo i da i to tako da \(Y_i\) uzima vrednost 1 ako i samo ako \(Y_i^*\) prelazi neku granicu \(\theta\). Dakle \[\pi_i=P\{Y_i=1\}=P\{Y_i^*>\theta\}\]. Pretpostavimo da je latentna varijabla u linearnoj vezi sa prediktorima \[Y_i^*=\bf{x}_i\bf{\beta}+U_i,\] gde su \(U_i\) greške, slučajne veličine sa funkcijom raspodele \(F\), koja ne mora biti normalna. Funkciju \(F\) zovemo link function. Sa \(\pi_i\) označimo verovatnoću da zavisna promenljiva \(i\)-te opservacija bude 1. Odavde imamo
\[\begin{align*} \pi_i &=P\{Y_i^*>0\} \\ &=P\{U_i>-\eta_i\}\\ &=1-F(-\eta_i), \end{align*}\]gde je \(\eta_i=\bf{x}_i\bf{\beta}\) linearni prediktor - fitovana vrednost. Ako je raspodela grešaka simetrična oko nule, onda važi \(F(u)=1-F(-u)\) i možemo napisati \[\pi_i=F(\eta_i)\]
Sada vidimo da se logistički model može posmatrati preko uopštenog modela sa latentnom varijablom ako pretpostavimo da greške imaju funkciju raspodele \[\pi_i=F(\eta_i)=\frac{e^{\eta_i}}{1+e^{\eta_i}},\] za \(\eta_i\in \mathbb{R}\). Ovo je funkcija raspodele slučajne promenljive sa logističkom raspodelom. Ova raspodela je simetrična i ima sličan oblik kao normalna, samo ima deblje repove. Dakle, kof logističke regresije link function je logit funkcija.
Fitovanje modela podacima
Pokušavamo da modelujemo verovatnoću da \(Y\) uzima vrednost 0 i 1 na osnovu uzorka. Objasnićemo kako se dobija funkcija verodostojnosti. Ako imamo niz Bernulijevih slučajnih veličina, gde sve imaju istu raspodelu, sa parametrom \(\pi\), onda je funkcija verodostojnosti \[\prod_{i=1}^{n}\pi^{y_i}(1-\pi)^{1-y_i}\] U tom slučaju, ocena za \(\pi\) je \(\hat{\pi}=n^{-1}\sum y_i\). Mi pretpostavljamo da u zavisnosti od vrednosti prediktora, zavisna promenljiva \(Y_i\) ima različitu Bernulijevu raspodelu. Ako imamo takav uzorak gde svaka opservacija potiče iz različite Bernulijeve raspodele, sa nepoznatim parametrom \(\pi_i\), tada je funkcija verodostojnosti \[\prod_{i=1}^{n}\pi_i^{y_i}(1-\pi_i)^{1-y_i}\] Sada treba da ocenimo sve nepoznate verovatnoće, a ocenili bismo \(\pi_i\) sa \(\hat{\pi}_i=1\), ako je \(y_i=1\), odnosno \(\hat{\pi}_i=0\), ako je \(y_i=0\) (imamo samo uzorak obima 1 za svaku od različitih Bernulijevih raspodela). U logističkom modelu mi imamo opservacije koje su iz različitih Bernulijevih raspodela, ali parametri tih raspodela nisu potpuno proizvoljni, kao malopre, nego su u vezi. Mi pretpostavljamo da oni zavise od nepoznatih parametara \(\bf{beta}\), \(\pi_i=1/(1+e^{-\bf{x}\bf{\beta}})\). Funkcija verodostojnosti ovog modela je
\[\begin{align*} L(\beta;\textbf{y},\textbf{X})&=\prod_{i=1}^{n}\pi_{i}^{y_{i}}(1-\pi_{i})^{1-y_{i}}\\ & =\prod_{i=1}^{n}\biggl(\frac{\exp(\textbf{X}_{i}\beta)}{1+\exp(\textbf{X}_{i}\beta)}\biggr)^{y_{i}}\biggl(\frac{1}{1+\exp(\textbf{X}_{i}\beta)}\biggr)^{1-y_{i}}. \end{align*}\]Verovatnoće Bernulijevih raspodela dobijemo maksimiziranjem ove funkcije po \(\bf{\beta}\); onda izražavamo te verovatnoće.
Objašnjenje: Recimo da imamo dat skup prediktora \(\textbf{X}_{i}\), vrednosti zavisne promenljive \(y_i\) (ovo je 0 ili 1) i tražimo (ocenjujemo) najbolji skup koeficijenata \(\beta\). Za neke odabrane vrednosi koeficijenata tada možemo izračunati i vrednosti predviđene modelom - koje predstavljaju verovatnoće jedinice zavisne promenljive. Najbolji skup koeficijenata \(\beta\) je onaj kojim dobijamo da za svako \(i\) za koje je \(y_i=0\) onda je i \(\pi_i\) blizu nule, i obrnuto za one \(i\) za koje \(y_i=1\) \(\pi_i\) je veliko. Takav skup prediktora upravo dobijemo maksimiziranjem funkcije \(L\).
Funkcija log-likelihood tada je
\[\begin{align*} \ell(\beta)&=\sum_{i=1}^{n}[y_{i}\log(\pi_{i})+(1-y_{i})\log(1-\pi_{i})]\\ & =\sum_{i=1}^{n}[y_{i}\textbf{X}_{i}\beta-\log(1+\exp(\textbf{X}_{i}\beta))]. \end{align*}\]Tačka (vektor \(\beta\)) ukojoj se dostiže maksimum funkcije \(L\) odnosno \(l\) se ne može lepo izraziti, koristi se na primer Njutnova metoda za nalaženje minimuma funkcije - ovaj metod se zove IRLS (Iteratively Reweighted Least Squares). Može se desiti da metoda ne konvergira ka rešenju. To može biti posledica multikolinearnosti, razređenosti (postoji puno nula u vrednostima prediktora)…
Primer
U bazi leukemia_remission.txt nalaze se podaci o 27 pacijenata koji boluju od leukemije. Zavisna promenljiva je da li je bolest u remisiji (0 ako nije 1 ako jeste). Imamo različite prediktore, koji su uglavnom dati u procentima - numerički su. Pravimo model logističke regresije. Koristimo funkciju glm a kao argument family=“binomial”.
leukemia <- read.table("Logisticka/leukemia_remission.txt", header=T)
attach(leukemia)
model.1 <- glm(REMISS ~ CELL + SMEAR + INFIL + LI + BLAST + TEMP, family="binomial")
summary(model.1)##
## Call:
## glm(formula = REMISS ~ CELL + SMEAR + INFIL + LI + BLAST + TEMP,
## family = "binomial")
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.95404 -0.66259 -0.02516 0.78184 1.57465
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 64.25808 74.96480 0.857 0.391
## CELL 30.83006 52.13520 0.591 0.554
## SMEAR 24.68632 61.52601 0.401 0.688
## INFIL -24.97447 65.28088 -0.383 0.702
## LI 4.36045 2.65798 1.641 0.101
## BLAST -0.01153 2.26634 -0.005 0.996
## TEMP -100.17340 77.75289 -1.288 0.198
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 21.594 on 20 degrees of freedom
## AIC: 35.594
##
## Number of Fisher Scoring iterations: 8confint.default(model.1) # based on asymptotic normality## 2.5 % 97.5 %
## (Intercept) -82.6702241 211.186392
## CELL -71.3530610 133.013183
## SMEAR -95.9024389 145.275071
## INFIL -152.9226458 102.973698
## LI -0.8490839 9.569992
## BLAST -4.4534852 4.430423
## TEMP -252.5662623 52.219462#confint(model.1) # based on profiling the least-squares estimation surfaceVidimo da je model napravljen ali treba objasniti šta se još dobija na izlazu.
Wald-ov test
Wald-ov test se koristi za testiranje značajnosti koeficijenata logističke regresije, tj. testiranje da li je koeficijent uz neki prediktor zapravo jednak nuli, kao t-test kod linearne regresije. Za ocene dobijene metodom maksimalne verodostojnosti količnik
\[\begin{equation*} Z=\frac{\hat{\beta}_{i}}{\textrm{s.e.}(\hat{\beta}_{i})} \end{equation*}\]se može koristiti kao test statistika za testiranje H_{0}: _{i}=0. Vrednosti odgovarajućih test statistika dobijaju se u koloni z value a p-vrednosti testa su u koloni Pr(>|z|). Odavde imamo i intervale povernja za ocenjene koeficijente
\[\begin{equation*} \hat{\beta}_{i}\pm z_{1-\alpha/2}\textrm{s.e.}(\hat{\beta}_{i}). \end{equation*}\]Vidimo da su p-vrednosti velike. Ne bavimo se sada izborom prediktora, probaćemo model samo sa prediktorom LI, jer on ima najmanju p-vrednost a i da bismo ga grafički prikazali.
Jednačina tog modela može se ovako napisati \[\begin{align*} P(1)&=\exp(Y')/(1+\exp(Y'))\\ Y'&= -3.78 + 2.90 LI \end{align*}\]model.2 <- glm(REMISS ~ LI, family="binomial")
summary(model.2)##
## Call:
## glm(formula = REMISS ~ LI, family = "binomial")
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.9448 -0.6465 -0.4947 0.6571 1.6971
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.777 1.379 -2.740 0.00615 **
## LI 2.897 1.187 2.441 0.01464 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 34.372 on 26 degrees of freedom
## Residual deviance: 26.073 on 25 degrees of freedom
## AIC: 30.073
##
## Number of Fisher Scoring iterations: 4plot(x=LI, y=REMISS,
panel.last = lines(sort(LI), fitted(model.2)[order(LI)]))
Na grafiku vidimo da mali vrednostima LI odgovara manja verovatnoća da bolest uđe u remisiju, a većim vrednostim LI, veća verovatnoća, sa nekim izuzceima velikih LI bez remisije.
Odds, Log Odds, Odds Ratio
Logistički model može se ekvivalentno prikazati i na druge načine. Prvi je
\[\begin{equation}\label{logmod1} \frac{\pi}{1-\pi}=\exp(\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{p-1}X_{p-1}). \end{equation}\]Šansu događaja sa verovatnoćom \(\pi\) definišemo kao broj \(\pi/(1-\pi)\). Dakle, prethodnom jednačinom vidimo da se logističkim modelom modeluju šanse događaja da opservacija sa ovim skupom prediktora upadne u kategoriju od interesa (da uzme vrednost 1). Ako je ovaj količnik veliki to znači da je brojilac mnogo veći od imenioca, pa se za taj skup prediktora očekuje da će pre pripadati kategoriji “uspeh”. Male vrednosti količnika znače da je imenilac dosta veći od brojioca, što znači da je \(\pi\) blizu nule, pa se za taj skup prediktora očekuje da pripada kategoriji neuspeha. Drugi način da se napiše jednačina modela je preko log odds
\[\begin{equation}\label{logmod2} \log\biggl(\frac{\pi}{1-\pi}\biggr)=\beta_{0}+\beta_{1}X_{1}+\ldots+\beta_{p-1}X_{p-1}. \end{equation}\]Odavde možemo videti ideju logističkog modela, a to je da se binarna promenljiva konvertuje u neprekidnu koja može uzimati vrednosti u celom \(\mathbb{R}\) i da se onda gleda linearna veza sa prediktorima. Dakle, sada dobijamo da je log odds linearna funkcija prediktora.
Definišemo još i količnik šansi (odds ratio). To je količnik šansi uspeha za neka dva skupa prediktora (jedan skup prediktora odgovara jednoj opservaciji, to su X_1,…,X_{p-1}), označimo ih sa \(\textbf{X}_{(1)}\) i \(\textbf{X}_{(2)}\). Taj količnik obeležavamo sa \(\theta\).
\[\begin{equation*} \theta=\frac{(\pi/(1-\pi))|_{\textbf{X}=\textbf{X}_{(1)}}}{(\pi/(1-\pi))|_{\textbf{X}=\textbf{X}_{(2)}}} \end{equation*}\]Ovaj količnik nam služi za interpretaciju vrednosti koeficijenata. Ako uzmemo da su \(\textbf{X}_{(1)}\) i \(\textbf{X}_{(2)}\) jednaki osim u vrednosti jednog prediktora, i to tako da se u vrednosti oni razlikuju za jedan, na primer u \(\textbf{X}_{(1)}\) \(i\)-ti prediktro prediktor je +1 u odnosu na \(i\)-ti prediktor u \(\textbf{X}_{(1)}\) . Tada se u količniku za \(\theta\) skoro sve skrati, a ostaje
\[\begin{equation*} \theta=\frac{\exp(\beta_i(X_i+1))}{\exp(\beta_iX_i)}=\exp(\beta_i). \end{equation*}\]Uopšte, Odds ratio može biti bilo koji pozitivan broj.
- Ako je u opisanom slučaju on jednak 1, to govori u prilog tome da nema veze između zavisne promenljive i pomenutog prediktora - to jest da je \(\beta_i=0\).
- Ako je je odds ratio veći od 1, to znači da je veći odds da opservacija sa jediničnim povećanjem u \(i\)-tom prediktoru pripada kategoriji uspeha, nego odds da druga opservacija (sa manjom vrednošću tog prediktora) pripada kategoriji uspeha. Odds se poveća \(\exp(\beta_i)\) puta za jedinično povećanje u \(i\)-tom prediktoru.
- Ako je odds ratio manji od 1, to znači da je manji odds da opservacija sa jediničnim povećanjem u \(i\)-tom prediktoru pripada kategoriji uspeha, nego odds da druga opservacija (sa manjom vrednošću tog prediktora) pripada kategoriji uspeha. Odds je veći \(\exp(\beta_i)\) puta za jedinično smanjenje u \(i\)-tom prediktoru.
Računamo odds ratio za naš model sa jednim prediktorom. Dobijamo vrednost 18.12449.
exp(coef(model.2)[2]) ## LI
## 18.12449exp(confint.default(model.2)[2,])## 2.5 % 97.5 %
## 1.770284 185.561725Interval poverenja za koeficijent pa ga koristimo kao interval poverenja za odds ratio Ona je veća od 1, što nam govori da su veće vrednosti LI bolje, jer je tada veći odds da bolest uđe u remisiju, i to za jedinično povećanje u \(LI\) 18.12 puta se povećavaju šanse. Ipak pošto vidimo da su vrednosti koje uzima \(LI\) između 0 i 2, nema smisla gledati jedinično povećanje. Više ima smisla gledati povećanje 0.1 jedinica.
- Ako je LI=0.9 šanse za remisiju su \(\exp\{-3.77714+2.89726*0.9\}=0.310\)
- Ako je LI=0.8 šanse za remisiju su \(\exp\{-3.77714+2.89726*0.8\}=0.232\)
Dobijamo da je odds ratio za povećanje LI za 0.1 \(\frac{0.310}{0.232}=1.336\). Šanse da bolest uđe u remisiju povećavaju se 1.336 puta.
Nekada sve što očekujemo od logističkog modela je da interpretiramo uticaje prediktora. To radimo na opisani način pomoću količnika šansi. Nekada se očekuje da predviđamo vrednosti za neke nove vrednosti skupa prediktora. Tada treba na osnovu ocenjene verovatnoće da se odlučimo za 0 ili 1. U tom slučaju biramo neku granicu, tako da za opservaciju čija je ocenjena verovatnoća veća od te granice predviđamo uspeh, inače neuspeh.
Likelihood Ratio (Deviance) Test
Ovaj test analogan je F testu kod MLR modela. U F testu bavili smo se razbijanjem ukupne disperzije (koristeći formulu za razbijanje sume kvadrata) na disperziju objašnjenu prediktorima onu koja ostaje neobjašnjena. Kod logističke regresije umesto suma kvadrata koristimo devijanse. Devijansom merimo odsustvo prilagođenosti podataka logističkom modelu.
LRT test koristi se da se testira nulta hipoteza da je bilo koji skup prediktora \(\beta\) jednak nuli. Neka je ukupan broj ocenjenih koeficijenata (to je 1 + broj prediktora) jednak \(p\), a u redukovanom modelu je \(r\). Nulta hipoteza nam je da je tačno \(p-r\) koeficijenata \(\beta\) jednako nuli. Test statistika je
\[\begin{equation*} \Lambda^{*}=-2(\ell(\hat{\beta}^{(0)})-\ell(\hat{\beta})), \end{equation*}\]gde je \(\ell(\hat{\beta})\) log likelihood funkcija potpunog modela a \(\ell(\hat{\beta}^{(0)})\) log likelihood funkcija modela pretpostavljenog nultom hipotezom. Ova test statistika ima \(\chi^{2}\) raspodelu sa \(p-r\) stepeni slobode. Radićemo sa modelom sa samo jednim prediktorom, pa sledećim pozivom funkcije anova se zapravo testira da li je bolji konstantni model, gde nema prediktora. Možda nije jasno šta su vrednosti predviđene modelom u modelu bez prediktora. Svakoj tački se tada dodeljuje ista verovatnoća, a to je udeo uspeha, jedinica u uzorku, a to je \(9/27=0.333333\).
anova(model.2, test="Chisq")## Analysis of Deviance Table
##
## Model: binomial, link: logit
##
## Response: REMISS
##
## Terms added sequentially (first to last)
##
##
## Df Deviance Resid. Df Resid. Dev Pr(>Chi)
## NULL 26 34.372
## LI 1 8.2988 25 26.073 0.003967 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1sum(residuals(model.2, type="deviance")^2) # 26.07296## [1] 26.07296model.2$deviance # 26.07296## [1] 26.07296sum(residuals(model.2, type="pearson")^2) # 23.93298## [1] 23.93298Kratko komentar: Vidimo da je p vrednost testa koja odgovara testiranju \(H_0: \beta_1=0\) različita od p vrednosti koju smo za isto testiranje dobili Wald-ovim testom. Uopšte, ova dva testa daju različite rezultate: Wald-ov test ne daje iste rezultate kao LR test gde je redukovani model za jedan prediktor manji od potpunog. Kod testova za MLR model imali smo da su t-test i F-test davali iste rezultate, ovde to nije slučaj.
Objasnićemo sve dobijene vrednosti. U kolonama \(Df\) i \(Resid.Df\) prikazani su stepeni slobode, koliko je u rezidualima, a koliko je podeljeno na prediktore. Svaki prediktor nosi po jedan stepen slobode, a ostatak od \(n\) je u rezidualima.
Funkcijom anova ne dobijamo vrednosti funkcija verodostojnosti, ali dobijamo vrednosti deviance za oba modela. Deviance se za neki model definiše kao \(-2*\text{log-likelihood}\). Test statistika se onda računa kao \(G^2=\text{deviance(reduced)}-\text{deviance(full)}\). Vrednost verodostojnosti se pritom računa u mmv oceni.
U koloni Resid. Dev u prvoj vrsti nalazi se vrednost deviance za redukovani model \[\text{deviance(reduced)}=-2\ell(\hat{\beta}^{(0)})=34.372\]. U drugoj vrsti nalazi se deviance za potpun model \[\text{deviance(full)}=-2\ell(\hat{\beta})=26.073\] Vrednost test statistike nalazi se u koloni Deviance i to je \(\Lambda^{*}=G^2=34.372-26.073=8.299\).
Sada ćemo opisati Deviance test u slučaju više prediktora i redukovanog modela koji sadrži prediktore.
Primer
disease <- read.table("Logisticka/DiseaseOutbreak.txt", header=T)
attach(disease)
Age.Middle <- Age*Middle
Age.Lower <- Age*Lower
Age.Sector <- Age*Sector
Middle.Sector <- Middle*Sector
Lower.Sector <- Lower*Sector
model.1 <- glm(Disease ~ Age + Middle + Lower + Sector + Age.Middle + Age.Lower +
Age.Sector + Middle.Sector + Lower.Sector, family="binomial")
model.2 <- glm(Disease ~ Age + Middle + Lower + Sector, family="binomial")
anova(model.2, model.1, test="Chisq")## Analysis of Deviance Table
##
## Model 1: Disease ~ Age + Middle + Lower + Sector
## Model 2: Disease ~ Age + Middle + Lower + Sector + Age.Middle + Age.Lower +
## Age.Sector + Middle.Sector + Lower.Sector
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 93 101.054
## 2 88 93.996 5 7.0583 0.2163Za poređenje dva modela sada koristimo anova funkciju sa dva parametra i kao argument test=“Chisq”. Potpun model ovde uključuje interakcije (ovde nisu kategorički prediktori, te interakcije nismo pominjali do sad), a manji model je bez interakcija.
U koloni Resid. Dev date su vrednosti deviance za oba modela. Veći model ima uvek manji deviance. U koloni Deviance nalazi se jedna vrednost i to je razlika dve vrednosti iz kolone Resid. Dev, vrednost test statistike. Broj stepeni slobode te test statistike je 5 - za toliko prediktora se razlikuju. Data je i p-vrednost testa koja je velika, što znači da prihvatamo nultu hipotezu da su neki koeficijenti jednaki nuli, dakle redukovani model je bolji.
Kada funkciju anova primenimo na model sa više prediktora dobijemo nešto slično kao kod MLR modela - Sequential Deviances. Odavde se takođe može pročitati vrednost test statistike, samo treba osigurati da su prediktori dati u redosledu tako da su oni iz manjeg modela svi na početku, uzastopno. Samo treba sabrati poslednjih nekoliko sequential deviances, za prediktore iz većeg modela koji nisu u manjem, i tako dobijemo test statistiku \(G^2 = 4.570+1.015+1.120+0.000+0.353 = 7.058\)
anova(model.1, test="Chisq")## Analysis of Deviance Table
##
## Model: binomial, link: logit
##
## Response: Disease
##
## Terms added sequentially (first to last)
##
##
## Df Deviance Resid. Df Resid. Dev Pr(>Chi)
## NULL 97 122.318
## Age 1 7.4050 96 114.913 0.006504 **
## Middle 1 1.8040 95 113.109 0.179230
## Lower 1 1.6064 94 111.502 0.205003
## Sector 1 10.4481 93 101.054 0.001228 **
## Age.Middle 1 4.5697 92 96.484 0.032542 *
## Age.Lower 1 1.0152 91 95.469 0.313666
## Age.Sector 1 1.1202 90 94.349 0.289878
## Middle.Sector 1 0.0001 89 94.349 0.993427
## Lower.Sector 1 0.3531 88 93.996 0.552339
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1detach(disease)Dijagnostika
Nakon što fitujemo model, moramo proveriti koliko dobro on odgovara podacima. Kod linearne regresije, dijagnostika je zasnovana na rezidualima i njihovoj sumi kvadrata. Kod logističke regresije postoji više tipova reziduala, pa i više tipova sume kvadrata reziduala
\(R^2\)
Kod logističkog modela \(R^2\) definiše se drugačije nego kod MLR mdoela. Jedan mogući način definisanja je (Likelihood ratio \(R^2\)) \[\begin{equation*} R^{2}=1-\frac{\ell(\hat{\beta})}{\ell(\hat{\beta_{0}})}. \end{equation*}\]gde je \(\ell(\hat{\beta_{0}})\) log likelihood modela samo sa interceptom (bez prediktora). Umesto količnika log likelihood-a možemo posmatrati i količnik deviance za dva modela (faktori -2 se skrate) pa dobijamo vrednost 0.24.
1-model.2$deviance/model.2$null.deviance## [1] 0.1738381Dakle, ideja je da se meri procentualna redukcija u devijansi Postoji još mogućih načina za definisanje \(R^2\) - te mere zovu se pseudo \(R^2\) vrednosti.
Raw residual
Ovo su jednostavno razlike stvarnih vrednosti zavisne promenljive \(y_i\) i ocenjenih verovatnoća \(\hat{\pi}_i\). \[\begin{equation*} r_{i}=y_{i}-\hat{\pi}_{i}. \end{equation*}\]Pearson residual
Problem nejednakosti varijanse u Raw residualima se rešava tako što podelimo rezidual sa njegovom standardnom devijacijom. Pirsonovi reziduali su \[\begin{equation*} p_{i}=\frac{r_{i}}{\sqrt{\hat{\pi}_{i}(1-\hat{\pi}_{i})}}. \end{equation*}\] U ovom pristup svaka opservacija tretira se kao jedan ishod binarne slučajne veličine. Drugi pristup je da se sve opservacije koje imaju iste vrednosti prediktora posmatraju kao jedna opservacija sa binomnom raspodelom. Recimo da smo poređali u niz sve \(p\)-torke prediktora koje se javljaju, i imamo ukupno \(n_i\) opservacija koje imaju vrednosti prediktora kao \(i\)-ta \(p\)-torka. Sa \(y_i\) sada označimo broj onih opservacija, od ukupno \(n_i\) kod kojih se desio uspeh (kom broju prediktora od njih \(n_i\) odgovara jedinica). Rezidual u ovom slučaju je \[\begin{equation*} p_{i}=\frac{y_{i}}{\sqrt{n_i\hat{\pi}_{i}(1-\hat{\pi}_{i})}}. \end{equation*}\]Ove reziduale koristimo kada ima puno opservacija koje imaju iste vrednosti prediktora. Ako su prediktori neprekidni, onda ih nema potrebe koristiti.
Kada sumiramo i kvadriramo Pirsonove reziduale dobijemo Pirsonovu statistiku. Rekli bismo da ona ima \(\chi\)^2 raspodelu sa \(n-p\) stepeni slobode i da su kritične velike vrednosti. Međutim ovaj test nije dobar za testiranje modela.
Deviance residual
Naziv potiče od činjenice da je suma ovih reziduala deviance modela (to je bilo u primeru ranije), odnosno da je suma kvadrata tih reziduala jednaka \(-2\times \text{log-likelihood}\). Kada fitujemo model logističke regresije, mi zapravo za poznate \(\bf{X}\) fitujemo funkciju \(\pi=\text{logit}^{-1}(\bf{X}\beta)\) tako da minimizujemo ukupni deviance, što je suma kvadrata deviance reziduala. Ideja je da se meri uticaj svake tačke na funkciju verodostojnosti Ispred formule stoji znak \(\pm\) jer se uzima da je deviance rezidual znaka kao i odgovarajući raw rezidual.
\[\begin{equation*} d_{i}=\pm\sqrt{2\biggl[y_{i}\log\biggl(\frac{y_{i}}{\hat{\pi}_{i}}\biggr)+(1-y_{i})\log\biggl(\frac{1-y_{i}}{1-\hat{\pi}_{i}}\biggr)\biggr]}. \end{equation*}\]Pošto \(y_i\) može biti samo 0 ili 1, pretodni izraz se može napisati i ovako
\[\begin{equation*} d_{i}=\pm\sqrt{-2\biggl[y_{i}\log\hat{\pi}_{i}+(1-y_{i})\log(1-\hat{\pi}_{i)}\biggr]}. \end{equation*}\]Vidimo da, ako imamo savršen slučaj gde je ocenjena verovatnoća 1 i \(y_i\) je 1 (ili slično ocenjena verovatnoća je nula i realizovana je nula), onda je deviance rezidual te tačke jednak nuli. Ako se vrednosti razlikuju - za \(y_i=1\) ocenjena verovatnoća je mala, i obrnuto, onda je vrednost \(d_i\) velika.
Ako imamo uzorak gde ima više opservacija sa istim vrednostima skupa prediktora, onda njih možemo posmatrati kao jednu opservaciju sa binomnom raspodelom, a deviance rezidual definišemo kao
\[\begin{equation*} d_{i}=\pm\sqrt{2\biggl[y_{i}\log\biggl(\frac{y_{i}}{n_i\hat{\pi}_{i}}\biggr)+(n_i-y_{i})\log\biggl(\frac{n_i-y_{i}}{n_i-n_i\hat{\pi}_{i}}\biggr)\biggr]}. \end{equation*}\]Vrednost deviance modela, kao i vrednost Pirsonove statistike ne možemo koristiti za testiranje. Jedan popularan test koji se koristi za ovo testiranje predložili su Hosmer i Lemeshow.
Crtamo grafike reziduala, Pearson i deviance za model o remisiji.
model.2 <- glm(REMISS ~ LI, family="binomial")
plot(1:27, residuals(model.2, type="pearson"), type="b")
plot(1:27, residuals(model.2, type="deviance"), type="b")
Hat values
Hat matrica u slučaju logističke regresije definiše se kao \(H = V^{\frac{1}{2}}X(X'VX)^{-1}X'V^{\frac{1}{2}}\). Za ovu matricu ne važi, kao kod linearne regresije da je \(\hat{\pi}=Hy\). Matrica koja bi ovo zadovoljavala i ne postoji, jer ocene logističkom regresijom nisu linearne. Ova matrica ipak ima sličnosti sa hat matricom kod linearne regresije. gde je \(V\) dijagonana matrica, na dijagonali se nalaze vrednosti \(\pi_i(1-\pi_i)\). Opet važi da je zbir elemenata na dijagonali matrice \(H\) jednak broju ocenjenih parametara. Vrednosti na dijagonali ove matrice zovemo kao i ranije, leverages. Interpretacija leverage vrednosti sada zavisi od ocenjene odgovarajuće verovatnoće \(\pi_i\), a kod linearne regresija matrica \(H\) nije zavisila od modela. Ako je \(0.1 < \pi < 0.9\) onda se vrednosti leverage interpretiraju kao u slučaju linearne regresije, tj. što su veće vrednosti leverages-a to smatramo da taj skup prediktora više odstupa od srednjeg prediktora. Ako su verovatnoće \(\pi_i\) jako male ili jako velike, onda te odgovarajuće leverage vrednosti više ne mere rastojanje u skupu prediktora (nije monotona funkcija rastojanja kao kod linearne regresija). Dakle, ako su ocenjene verovatnoće manje od 0.1 ili veće od 0.9 mogu se dobiti male vrednosti leverage za neke opservacije koje jako odstupaju od drugih u skupu prediktora, i obrnuto. U R-u možemo ručno izračunati ovu matricu
beta=model.2$coefficients
X=model.matrix(model.2)
pi <- 1/(1+exp(-X%*%beta))
v <- sqrt(pi*(1-pi))
VX <- X*as.numeric(v)
H <- VX%*%solve(crossprod(VX,VX),t(VX))
diag(H)## 1 2 3 4 5 6
## 0.14983926 0.09217689 0.05405339 0.05655414 0.07542925 0.05820517
## 7 8 9 10 11 12
## 0.05142244 0.14983926 0.05405339 0.05843326 0.05655414 0.06250193
## 13 14 15 16 17 18
## 0.05711783 0.05405339 0.05456644 0.14983926 0.05843326 0.05142244
## 19 20 21 22 23 24
## 0.05820517 0.05456644 0.05711783 0.05820517 0.05142244 0.12728535
## 25 26 27
## 0.14033061 0.05181772 0.05655414hatvalues(model.2)## 1 2 3 4 5 6
## 0.14983953 0.09217662 0.05405333 0.05655415 0.07542902 0.05820525
## 7 8 9 10 11 12
## 0.05142232 0.14983953 0.05405333 0.05843344 0.05655415 0.06250175
## 13 14 15 16 17 18
## 0.05711809 0.05405333 0.05456630 0.14983953 0.05843344 0.05142232
## 19 20 21 22 23 24
## 0.05820525 0.05456630 0.05711809 0.05820525 0.05142232 0.12728511
## 25 26 27
## 0.14033048 0.05181762 0.05655415Leverage vrednosti koristimo za standardizovanje reziduala.
Studentizovani reziduali
Studentizovani Pirsonovi reziduali su
\[\begin{equation*} sp_{i}=\frac{p_{i}}{\sqrt{1-h_{i,i}}}. \end{equation*}\]Studentizovani deviance reziduali su
\[\begin{equation*} sd_{i}=\frac{d_{i}}{\sqrt{1-h_{i, i}}}. \end{equation*}\]Bolje je koristiti studentizovane deviance reziduale nego Pirsonove jer se smatra da su više simetrični.
Dijagnostika izostavljanjem po jedne opservacije
Kod linearne regresije koristili smo metod izbacivanja po jedne opservacije kao meru uticaja neke tačke. Upoređivali smo modele sa i bez te opservacije i gledali kako se menjaju reziduali, ocenjeni koeficijenti, fitovane vrednosti. Kukovo rastojanje neke opservacije u modelu koristi se kao mera njene uticajnsoti. Izraz za Kukovo rastojanje je gotovo isti, samo je izraz za rezidual drugačiji - koristimo Pirsonov rezidual. Formulu za Kukovo rastojanje kod linearne regresije dobijamo samo kad \(p_i\) zamenimo sa rezidualima podeljenim sa \(\sqrt{MSE}\).
\[\begin{equation*} \textrm{C}_{i}=\frac{p_{i}^{2}h _{i,i}}{p(1-h_{i,i})^{2}} \end{equation*}\]Case-control sampling
Case je naziv za grupu od interesa, jedinicu, a control za nulu. Pretpostavimo da ocenjujemo verovatnoće za neki redak događaj, to jest događaj male verovatnoće. Da bismo na osnovu uzorka mogli da pravimo model treba nam neki broj opservacija kod kojih se desio taj redak događaj - da bismo prikupili informacije o tome kakve vrednosti prediktora dovode do realizacije događaja. Recimo da bolest napada jednog čoveka u 10000. Ako uzorak biramo slučajno, biće nam potreban uzorak velikog obima. Ideja je da se uzorak bira drugačije - ne slučajno, nego da se uspesi ubacuju u uzorak malo češće. Jedno pravilo je da se uzima pet ili šest puta više controls nego cases, dakle da uzimamo uzorak tako da je svaki šesti ili sedmi element jedinica, a ostali su nule. Iako na ovaj način imamo disbalansirane podatke - nije PSU, ipak ćemo dobiti dobre ocene koeficijenata uz prediktora. Slobodan član će biti netačan, ali se može popraviti jednostavnom transformacijom. U sledećoj jednačini \(\pi\) je stvarni procenat jedinica (cases) u populaciji, a \(\hat{\pi}\) je procenat jedinica u našem uzorku.
\[\hat{\beta}^*_0=\hat{\beta}_0+\log\frac{\pi}{1-\pi}-\log\frac{\hat{\pi}}{1-\hat{\pi}}\]
Ovo se može primetiti sa slike. Disperzija ocena parametara zavisi od broja jedinica u uzorku, koje čine manju klasu. Na grafiku vidimo kako se ponaša disperzija koeficijenata u zavisnosti od odnosa control/case. Ako je ovaj odnos jednak 5 ili 6 onda je uzoračka disperzija koeficijenata jednaka teorijskoj. Ako uzimamo još veći broj control, kao što bismo da radimo sa prostim slučajnim uzorkom, onda bi ocenjena disperzija bila manja nego što jeste.
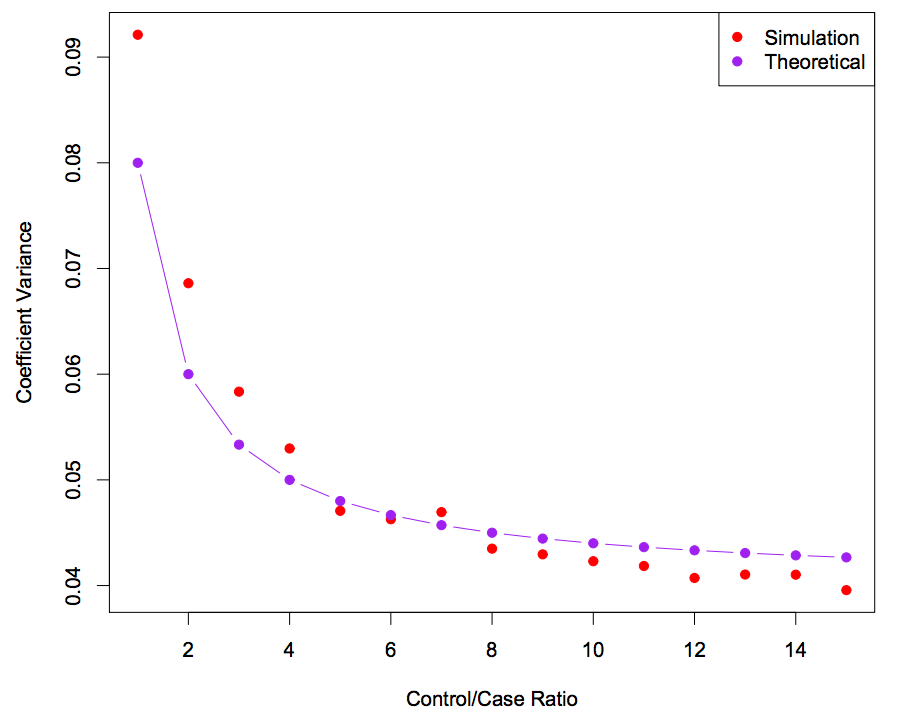{kind=link}
Primer
Sprovedeno je istraživanje da se ispita uticaj toksične materije na insekte. Prediktor je šest različitih nivoa doza materije kojoj su bili izloženi, a zavisne promenljiva indikator - da li je insekt uginuo ili ne.
toxicity <- read.table("Logisticka/toxicity.txt", header=T)
attach(toxicity)
Survivals <- SampSize - Deaths
y <- cbind(Deaths, Survivals)
model.1 <- glm(y ~ Dose, family="binomial")
summary(model.1)##
## Call:
## glm(formula = y ~ Dose, family = "binomial")
##
## Deviance Residuals:
## 1 2 3 4 5 6
## -0.5092 -0.1115 0.7461 -0.2869 0.4744 -0.5599
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.64367 0.15610 -16.93 <2e-16 ***
## Dose 0.67399 0.03911 17.23 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 383.0695 on 5 degrees of freedom
## Residual deviance: 1.4491 on 4 degrees of freedom
## AIC: 39.358
##
## Number of Fisher Scoring iterations: 3Dobijamo i intervale poverenja za ocenjene koeficijente.
confint.default(model.1) # based on asymptotic normality## 2.5 % 97.5 %
## (Intercept) -2.9496351 -2.3377149
## Dose 0.5973404 0.7506451confint(model.1) # based on profiling the least-squares estimation surface## Waiting for profiling to be done...## 2.5 % 97.5 %
## (Intercept) -2.9554809 -2.3432165
## Dose 0.5985828 0.7519688U sledećoj tabeli prikazane su vrednosti. Ovde imamo situaciju kada je i prediktor kategorički, pa se ponavljaju iste vrednosti prediktora i ona možemo da poredimo na osnovu uzorka ocenjenu verovatnoću i onu ocenjenu modelom. To se takođe može lepo videti i na grafiku. Sada ne crtamo zavisnu promenljivu na y osi, nego uzorački ocenjene verovatnoće.
cbind(Dose, SampSize, Deaths, Deaths/SampSize, fitted(model.1))## Dose SampSize Deaths
## 1 1 250 28 0.112 0.1224230
## 2 2 250 53 0.212 0.2148914
## 3 3 250 93 0.372 0.3493957
## 4 4 250 126 0.504 0.5130710
## 5 5 250 172 0.688 0.6739903
## 6 6 250 197 0.788 0.8022286plot(x=Dose, y=Deaths/SampSize,
panel.last = lines(sort(Dose), fitted(model.1)[order(Dose)]))
Možemo izračunati i količnik šansi za prediktor Dose, da bismo videli da li je to faktor rizika, to jest koliko se povećavaju šanse jedinice za jedinično povećanje doze. Računamo količnik šansi za ovaj prediktor i interval poverenja za količnik šansi.
exp(coef(model.1)[2])## Dose
## 1.962056exp(confint.default(model.1)[2,])## 2.5 % 97.5 %
## 1.817279 2.118366detach(toxicity)Zaključujemo da se za jedinično povećanje doze, šanse smrti insekta povećavaju 1.9621 puta.
Primer (https://stats.idre.ucla.edu/r/dae/logit-regression/)
Na osnovu nekih prediktora kao što su rezultati na testu GRE (gre), prosek studenta (gpa) i rang fakulteta koji su pohađali (rank) hoćemo da ispitamo šanse studenta da upadne na postdiplomske studije na fakultetu X.
mydata <- read.csv("https://stats.idre.ucla.edu/stat/data/binary.csv")
## view the first few rows of the data
head(mydata)## admit gre gpa rank
## 1 0 380 3.61 3
## 2 1 660 3.67 3
## 3 1 800 4.00 1
## 4 1 640 3.19 4
## 5 0 520 2.93 4
## 6 1 760 3.00 2Pravimo logistički model.
mydata$rank <- factor(mydata$rank)
mylogit <- glm(admit ~ gre + gpa + rank, data = mydata, family = "binomial")
summary(mylogit)##
## Call:
## glm(formula = admit ~ gre + gpa + rank, family = "binomial",
## data = mydata)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.6268 -0.8662 -0.6388 1.1490 2.0790
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.989979 1.139951 -3.500 0.000465 ***
## gre 0.002264 0.001094 2.070 0.038465 *
## gpa 0.804038 0.331819 2.423 0.015388 *
## rank2 -0.675443 0.316490 -2.134 0.032829 *
## rank3 -1.340204 0.345306 -3.881 0.000104 ***
## rank4 -1.551464 0.417832 -3.713 0.000205 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 499.98 on 399 degrees of freedom
## Residual deviance: 458.52 on 394 degrees of freedom
## AIC: 470.52
##
## Number of Fisher Scoring iterations: 4Iz vrednosti koeficijenata vidimo da za jedan poen više na GRE testu, log šanse za prijem na univerzitet X povećavaju se za 0.002. Za jedinično povećanje u proseku, log šanse za prijem povećavaju se za 0.824.
Primer (http://127.0.0.1:20173/library/ISLR/html/Smarket.html)
require(ISLR)## Loading required package: ISLRnames(Smarket)## [1] "Year" "Lag1" "Lag2" "Lag3" "Lag4" "Lag5"
## [7] "Volume" "Today" "Direction"summary(Smarket)## Year Lag1 Lag2
## Min. :2001 Min. :-4.922000 Min. :-4.922000
## 1st Qu.:2002 1st Qu.:-0.639500 1st Qu.:-0.639500
## Median :2003 Median : 0.039000 Median : 0.039000
## Mean :2003 Mean : 0.003834 Mean : 0.003919
## 3rd Qu.:2004 3rd Qu.: 0.596750 3rd Qu.: 0.596750
## Max. :2005 Max. : 5.733000 Max. : 5.733000
## Lag3 Lag4 Lag5
## Min. :-4.922000 Min. :-4.922000 Min. :-4.92200
## 1st Qu.:-0.640000 1st Qu.:-0.640000 1st Qu.:-0.64000
## Median : 0.038500 Median : 0.038500 Median : 0.03850
## Mean : 0.001716 Mean : 0.001636 Mean : 0.00561
## 3rd Qu.: 0.596750 3rd Qu.: 0.596750 3rd Qu.: 0.59700
## Max. : 5.733000 Max. : 5.733000 Max. : 5.73300
## Volume Today Direction
## Min. :0.3561 Min. :-4.922000 Down:602
## 1st Qu.:1.2574 1st Qu.:-0.639500 Up :648
## Median :1.4229 Median : 0.038500
## Mean :1.4783 Mean : 0.003138
## 3rd Qu.:1.6417 3rd Qu.: 0.596750
## Max. :3.1525 Max. : 5.733000?Smarket## starting httpd help server ...## donepairs(Smarket,col=Smarket$Direction)
# Logistic regression
glm.fit=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,
data=Smarket,family=binomial)
summary(glm.fit)##
## Call:
## glm(formula = Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 +
## Volume, family = binomial, data = Smarket)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.446 -1.203 1.065 1.145 1.326
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.126000 0.240736 -0.523 0.601
## Lag1 -0.073074 0.050167 -1.457 0.145
## Lag2 -0.042301 0.050086 -0.845 0.398
## Lag3 0.011085 0.049939 0.222 0.824
## Lag4 0.009359 0.049974 0.187 0.851
## Lag5 0.010313 0.049511 0.208 0.835
## Volume 0.135441 0.158360 0.855 0.392
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1731.2 on 1249 degrees of freedom
## Residual deviance: 1727.6 on 1243 degrees of freedom
## AIC: 1741.6
##
## Number of Fisher Scoring iterations: 3glm.probs=predict(glm.fit,type="response")
glm.probs[1:5]## 1 2 3 4 5
## 0.5070841 0.4814679 0.4811388 0.5152224 0.5107812glm.pred=ifelse(glm.probs>0.5,"Up","Down")
attach(Smarket)
table(glm.pred,Direction)## Direction
## glm.pred Down Up
## Down 145 141
## Up 457 507mean(glm.pred==Direction)## [1] 0.5216# Make training and test set
train = Year<2005
glm.fit=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,
data=Smarket,family=binomial, subset=train)
glm.probs=predict(glm.fit,newdata=Smarket[!train,],type="response")
glm.pred=ifelse(glm.probs >0.5,"Up","Down")
Direction.2005=Smarket$Direction[!train]
table(glm.pred,Direction.2005)## Direction.2005
## glm.pred Down Up
## Down 77 97
## Up 34 44mean(glm.pred==Direction.2005)## [1] 0.4801587#Fit smaller model
glm.fit=glm(Direction~Lag1+Lag2,
data=Smarket,family=binomial, subset=train)
glm.probs=predict(glm.fit,newdata=Smarket[!train,],type="response")
glm.pred=ifelse(glm.probs >0.5,"Up","Down")
table(glm.pred,Direction.2005)## Direction.2005
## glm.pred Down Up
## Down 35 35
## Up 76 106mean(glm.pred==Direction.2005)## [1] 0.5595238106/(76+106)## [1] 0.5824176Primer (https://www.rdocumentation.org/packages/glmpath/versions/0.98/topics/heart.data)
U ovoj bazi dati su podaci o 160 ljudi koji su imali infarkt (cases) i 304 ljudi koji nisu imali infakrt (controls) uzrasta od 15 do 64 iz Južne Afrike početkom osamdesetih. Dati su podaci o vrednosti 7 prediktora kod tih ljudi. Cilj je identifikovati uticaj različitih faktora rizika za infarkt. Procenat onih koji imaju infarkt je \(\pi=0.05\), ali vidimo da je procenat ispitanika koji su imali infarkt prema podacima 35%, \(\hat{\pi}=0.35\) - dakle radi se o case control sampling.
library("glmpath")## Loading required package: survival##
## Attaching package: 'survival'## The following object is masked _by_ '.GlobalEnv':
##
## leukemiadata("heart.data")
pairs(heart.data$x,col=heart.data$y+3)
Na grafiku vidimo matricu prediktora, a zavisna promenljiva je kodirana bojom zelena je za one koji nisu imali infarkt a plava za one koji su imali. Prediktor famhist je binarni, indikator da li je u porodici bilo infarkta. Na osnovu ocenjenih vrednost koeficijenata sada, možemo govoriti o svakom faktoru rizika koristeći količnik šansi.
heartfit <- glm ( y~x, data = heart.data, family = binomial )
summary ( heartfit )##
## Call:
## glm(formula = y ~ x, family = binomial, data = heart.data)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.7781 -0.8213 -0.4387 0.8889 2.5435
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -6.1507209 1.3082600 -4.701 2.58e-06 ***
## xsbp 0.0065040 0.0057304 1.135 0.256374
## xtobacco 0.0793764 0.0266028 2.984 0.002847 **
## xldl 0.1739239 0.0596617 2.915 0.003555 **
## xadiposity 0.0185866 0.0292894 0.635 0.525700
## xfamhist 0.9253704 0.2278940 4.061 4.90e-05 ***
## xtypea 0.0395950 0.0123202 3.214 0.001310 **
## xobesity -0.0629099 0.0442477 -1.422 0.155095
## xalcohol 0.0001217 0.0044832 0.027 0.978350
## xage 0.0452253 0.0121298 3.728 0.000193 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 596.11 on 461 degrees of freedom
## Residual deviance: 472.14 on 452 degrees of freedom
## AIC: 492.14
##
## Number of Fisher Scoring iterations: 5Nominalna logistička regresija (Multinomial Logistic Regression)
https://en.wikipedia.org/wiki/Multinomial_logistic_regression
https://stats.idre.ucla.edu/r/dae/multinomial-logistic-regression/